本系列文章是在学习数据结构和算法时记录的学习笔记,概念讲解部分主要引用自《极客时间》的相关专栏,代码实践部分由本人采用 Python 实现。
版权归极客时间所有。
概念
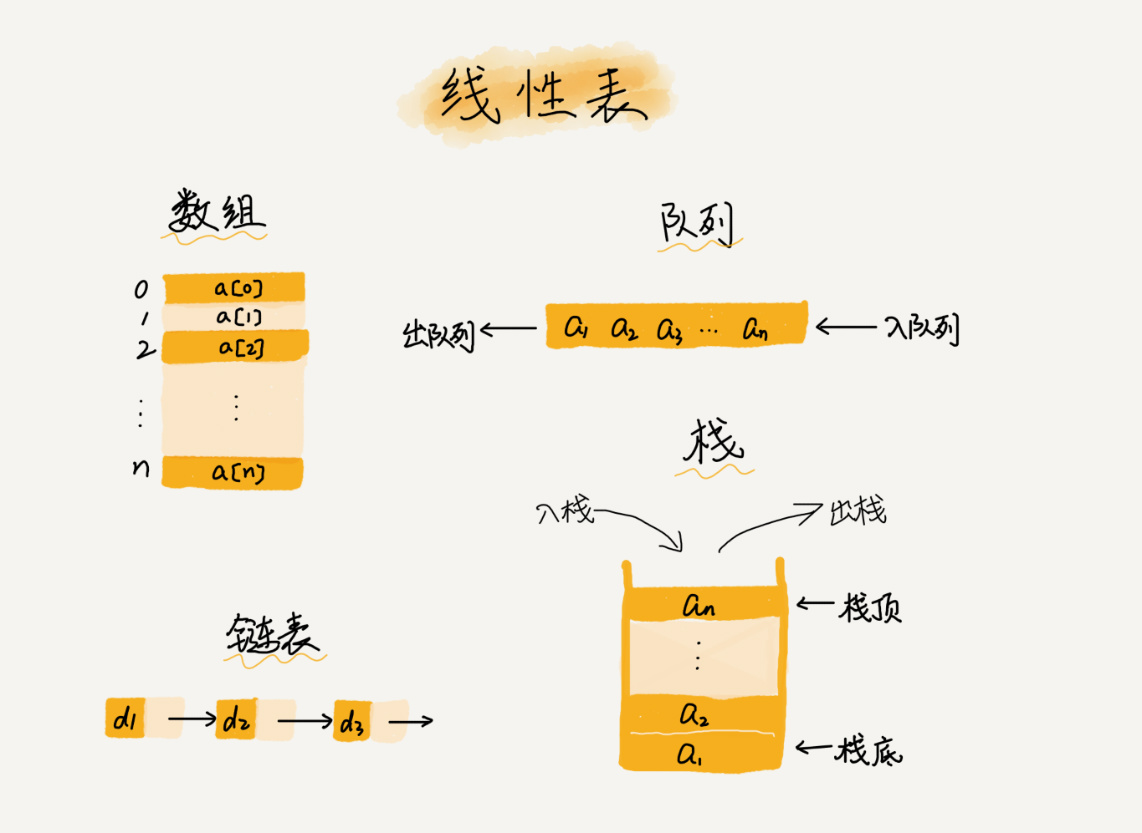
链表(Linked List)与数组一样,也是一种线性表数据结构,不过它不用一组连续的内存空间,而是通过指针的形式,将零散的内存块串联起来。
每一个内存块称为链表的节点。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的相邻结点的地址,记录下一个节点的指针叫作后继指针 next,记录上一个节点的指针叫作前驱指针 previous。
最常见的链表结构有:单链表、双向链表和循环链表。
单链表(Linked List)
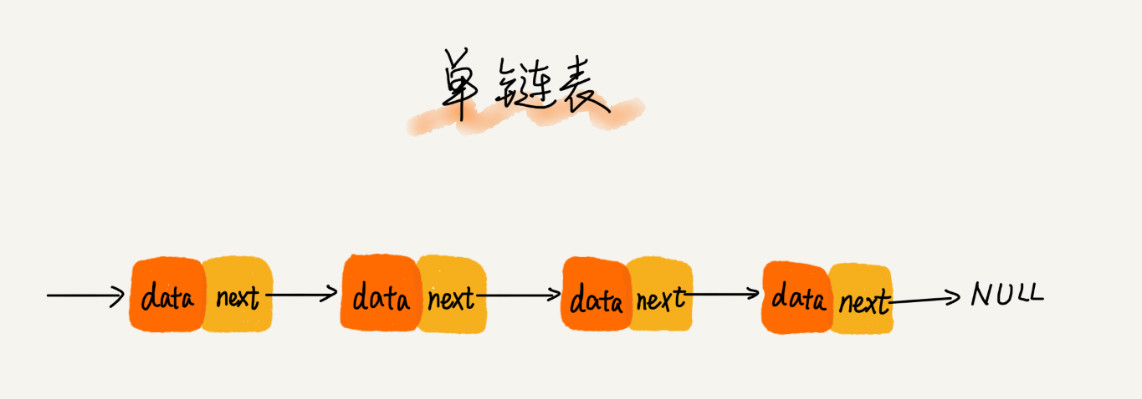
单链表的特点:
- 节点存储内容:当前节点的数据
data、后继指针next - 头结点:记录链表
基地址,有了它,我们就可以遍历得到整条链表 - 两个尾结点:后继指针指向
空地址NULL,遍历时作为尾结点的判断条件
双向链表(Doubly Linked List)

双向链表的特点:
- 节点存储内容:当前节点的数据
data、后继指针next、前驱指针previous,相比于单链表,双向链表会占用更多的内存空间 - 头结点:记录链表
基地址,前驱指针指向空地址NULL,有了它,我们就可以遍历得到整条链表 - 尾结点:后继指针指向
空地址NULL,遍历时作为尾结点的判断条件
复杂度分析
相比于数组,链表主要有以下优势:
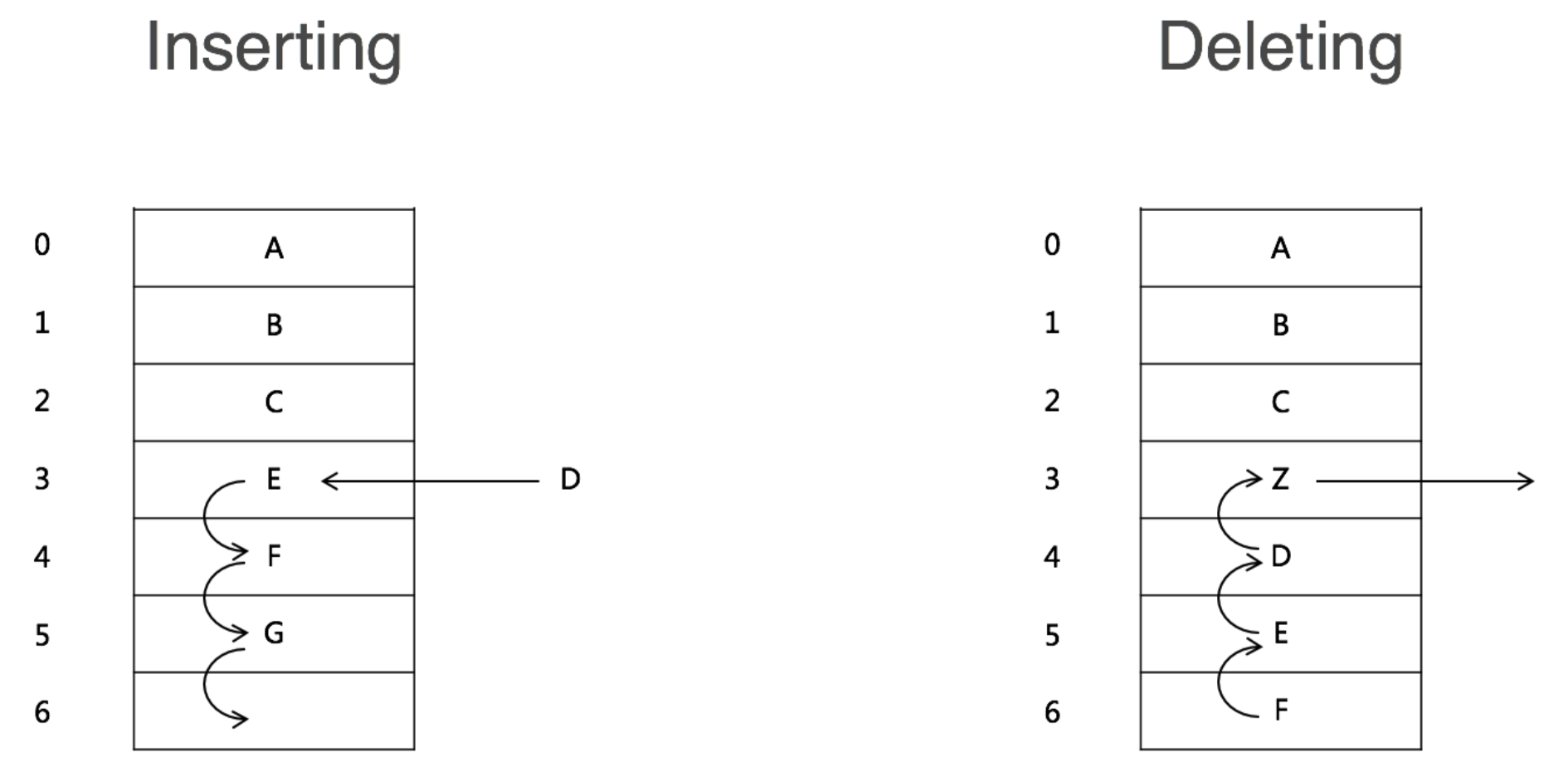
- 改善“插入”和“删除”的效率
- 不受内存连续性的限制,可以存储大量元素,例如 blockchain
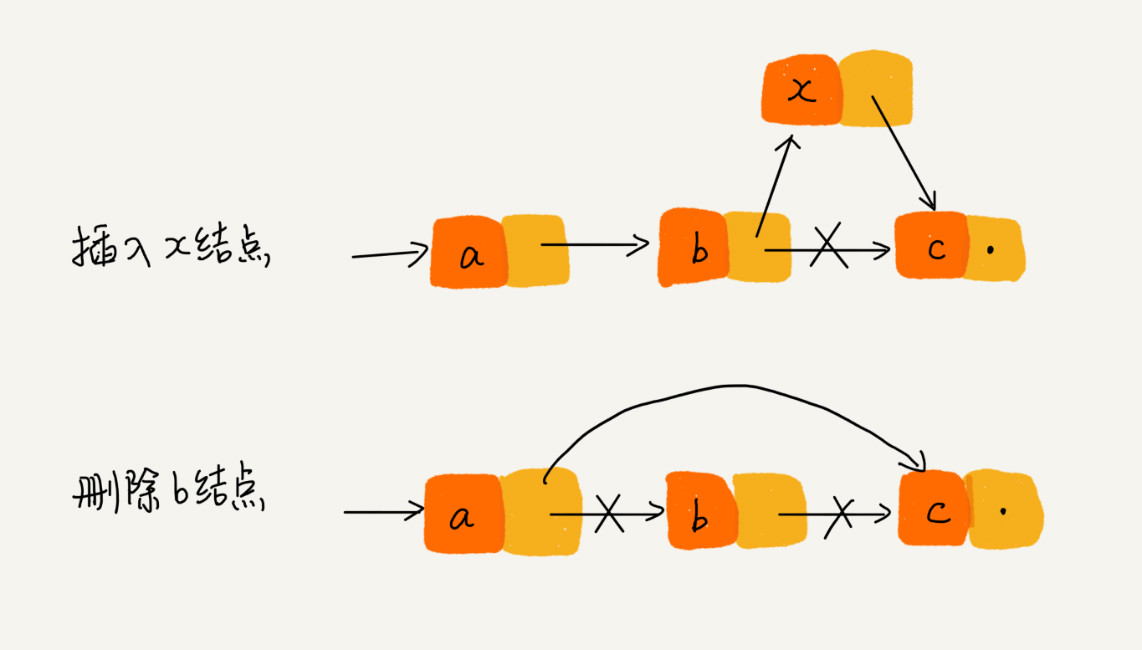
对应的弊端就是,随机访问效率较低,需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点。
单链表和双向链表在随机访问、查询操作时的时间复杂度相同:
- Access: O(n)
- Search: O(n)
在对链表进行“删除”操作时,存在两种情况:
(1)删除结点中“值等于某个给定值”的结点 q
(2)删除给定指针指向的结点 q
对于第一种情况,不管是单链表还是双向链表,为了查找到值等于给定值的结点,都需要从头结点开始一个一个依次遍历对比,直到找到值等于给定值的结点,然后再进行删除操作。查询时间复杂度 O(n),删除时间复杂度 O(1),因此总体时间复杂度为 O(1)。
对于第二种情况,已经确定了要删除的结点,但是删除某个结点 q 需要知道其前驱节点,因此在此情况下单链表和双向链表就存在较大差异:
- 单链表:需要从头节点依次遍历,找到 q 节点的前驱节点 p(p->next = q);查询时间复杂度 O(n),删除时间复杂度 O(1),因此总体时间复杂度为 O(n)。
- 双向链表:可直接获取 q 节点的前驱节点 p(q->previous);查询时间复杂度 O(1),删除时间复杂度 O(1),因此总体时间复杂度为 O(n)。
删除的伪代码:
1 | // 单链表 |
在对链表进行“插入”操作时,比如在链表的某个指定结点(q)前面插入一个结点(x),双向链表也有更大的优势:
- 单链表:需要从头节点依次遍历,找到 q 节点的前驱节点 p(p->next = q);查询时间复杂度 O(n),插入时间复杂度 O(1),因此总体时间复杂度为 O(n)。
- 双向链表:可直接获取 q 节点的前驱节点 p(q->previous);查询时间复杂度 O(1),插入时间复杂度 O(1),因此总体时间复杂度为 O(1)。
插入的伪代码:
1 | // 单链表 |
实战
典型问题
1、实现单链表,支持增删操作 😊
在 Python 语言中没有链表的数据结构,需要模拟进行实现。
定义单链表:
1 | class ListNode: |
创建单链表(5->4->3->2->1->None):

1 | head = None |
遍历单链表:
1 | # 输出 5、4、3、2、1 |
插入单链表
插入单链表,将 20 插入到 3 和 2 之间:

1 | # head 当前对应节点 5 |
2、实现单链表反转 😊
点击查看
Input: 1->2->3->4->5->NULL
Output: 5->4->3->2->1->NULL
1 | def reverseList(head: ListNode) -> ListNode: |
LeetCode: 206. Reverse Linked List
3、实现双向链表、循环链表,支持增删操作 🤔
TODO
定义双向链表:
1 | class BiNode(object): |
4、实现两个有序的链表合并为一个有序链表 🤔
TODO
5、实现求链表的中间结点 🤔
TODO
LeetCode
引用
- 数据结构与算法之美 | 05 | 数组:为什么很多编程语言中数组都从0开始编号?
- 算法面试通关40讲 | 05 | 理论讲解:数组 & 链表
- 算法面试通关40讲 | 06 | 反转一个单链表&判断链表是否有环
- 数据结构与算法之美 | Day 1:数组和链表