ApiTestEngine不是接口测试框架么,也能实现性能测试?
是的,你没有看错,ApiTestEngine集成了Locust性能测试框架,只需一份测试用例,就能同时实现接口自动化测试和接口性能测试,在不改变Locust任何特性的情况下,甚至比Locust本身更易用。
如果你还没有接触过Locust这款性能测试工具,那么这篇文章可能不适合你。但我还是强烈推荐你了解一下这款工具。简单地说,Locust是一款采用Python语言编写实现的开源性能测试工具,简洁、轻量、高效,并发机制基于gevent协程,可以实现单机模拟生成较高的并发压力。关于Locust的特性介绍和使用教程,我之前已经写过不少,你们可以在我的博客中找到对应文章。
如果你对实现的过程没有兴趣,可以直接跳转到文章底部,看最终实现效果章节。
灵感来源
在当前市面上的测试工具中,接口测试和性能测试基本上是两个泾渭分明的领域。这也意味着,针对同一个系统的服务端接口,我们要对其实现接口自动化测试和接口性能测试时,通常都是采用不同的工具,分别维护两份测试脚本或用例。
之前我也是这么做的。但是在做了一段时间后我就在想,不管是接口功能测试,还是接口性能测试,核心都是要模拟对接口发起请求,然后对接口响应内容进行解析和校验;唯一的差异在于,接口性能测试存在并发的概念,相当于模拟了大量用户同时在做接口测试。
既然如此,那接口自动化测试用例和接口性能测试脚本理应可以合并为一套,这样就可以避免重复的脚本开发工作了。
在开发ApiTestEngine的过程中,之前的文章也说过,ApiTestEngine完全基于Python-Requests库实现HTTP的请求处理,可以在编写接口测试用例时复用到Python-Requests的所有功能特性。而之前在学习Locust的源码时,发现Locust在实现HTTP请求的时候,也完全是基于Python-Requests库。
在这一层关系的基础上,我提出一个大胆的设想,能否通过一些方式或手段,可以使ApiTestEngine中编写的YAML/JSON格式的接口测试用例,也能直接让Locust直接调用呢?
灵感初探
想法有了以后,就开始探索实现的方法了。
首先,我们可以看下Locust的脚本形式。如下例子是一个比较简单的场景(截取自官网首页)。
1 | from locust import HttpLocust, TaskSet, task |
在Locust的脚本中,我们会在TaskSet子类中描述单个用户的行为,每一个带有@task装饰器的方法都对应着一个HTTP请求场景。而Locust的一个很大特点就是,所有的测试用例脚本都是Python文件,因此我们可以采用Python实现各种复杂的场景。
等等!模拟单个用户请求,而且还是纯粹的Python语言,我们不是在接口测试中已经实现的功能么?
例如,下面的代码就是从单元测试中截取的测试用例。
1 | def test_run_testset(self): |
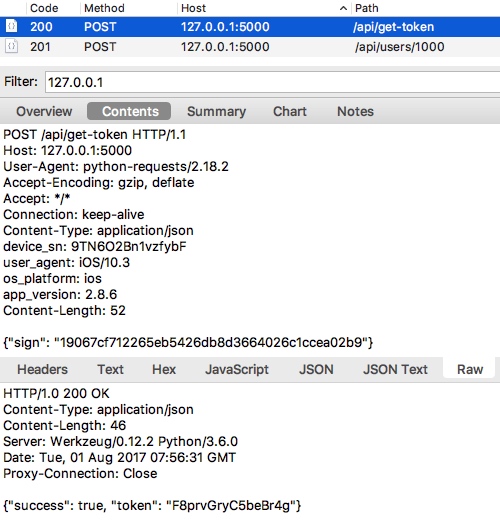
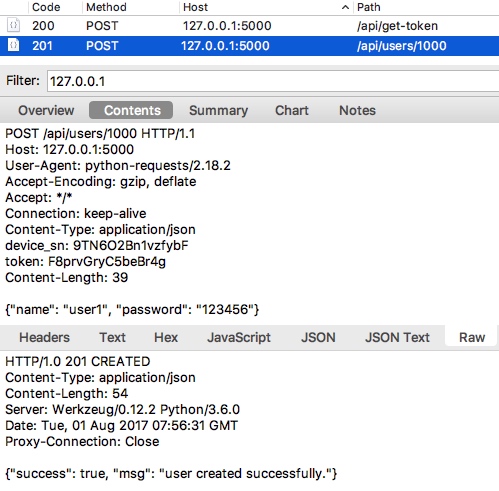
test_runner.run_testset是已经在ApiTestEngine中实现的方法,作用是传入测试用例(YAML/JSON)的路径,然后就可以加载测试用例,运行整个测试场景。并且,由于我们在测试用例YAML/JSON中已经描述了validators,即接口的校验部分,因此我们也无需再对接口响应结果进行校验描述了。
接下来,实现方式就非常简单了。
我们只需要制作一个locustfile.py的模板文件,内容如下。
1 | #coding: utf-8 |
可以看出,整个文件中,只有测试用例文件的路径是与具体测试场景相关的,其它内容全都可以不变。
于是,针对不同的测试场景,我们只需要将testcase_file_path替换为接口测试用例文件的路径,即可实现对应场景的接口性能测试。
1 | ➜ ApiTestEngine git:(master) ✗ locust -f locustfile.py |
后面的操作就完全是Locust的内容了,使用方式完全一样。
优化1:自动生成locustfile
通过前面的探索实践,我们基本上就实现了一份测试用例同时兼具接口自动化测试和接口性能测试的功能。
然而,在使用上还不够便捷,主要有两点:
- 需要手工修改模板文件中的
testcase_file_path路径; locustfile.py模板文件的路径必须放在ApiTestEngine的项目根目录下。
于是,我产生了让ApiTestEngine框架本身自动生成locustfile.py文件的想法。
在实现这个想法的过程中,我想过两种方式。
第一种,通过分析Locust的源码,可以看到Locust在main.py中具有一个load_locustfile方法,可以加载Python格式的文件,并提取出其中的locust_classes(也就是Locust的子类);后续,就是将locust_classes作为参数传给Locust的Runner了。
若采用这种思路,我们就可以实现一个类似load_locustfile的方法,将YAML/JSON文件中的内容动态生成locust_classes,然后再传给Locust的Runner。这里面会涉及到动态地创建类和添加方法,好处是不需要生成locustfile.py中间文件,并且可以实现最大的灵活性,但缺点在于需要改变Locust的源码,即重新实现Locust的main.py中的多个函数。虽然难度不会太大,但考虑到后续需要与Locust的更新保持一致,具有一定的维护工作量,便放弃了该种方案。
第二种,就是生成locustfile.py这样一个中间文件,然后将文件路径传给Locust。这样的好处在于我们可以不改变Locust的任何地方,直接对其进行使用。与Locust的传统使用方式差异在于,之前我们是在Terminal中通过参数启动Locust,而现在我们是在ApiTestEngine框架中通过Python代码启动Locust。
具体地,我在setup.py的entry_points中新增了一个命令locusts,并绑定了对应的程序入口。
1 | entry_points={ |
在ate/cli.py中新增了main_locust函数,作为locusts命令的入口。
1 | def main_locust(): |
若你执行locusts -V或locusts -h,会发现效果与locust的特性完全一致。
1 | $ locusts -V |
事实上,通过上面的代码(main_locust)也可以看出,locusts命令只是对locust进行了一层封装,用法基本等价。唯一的差异在于,当-f参数指定的是YAML/JSON格式的用例文件时,会先转换为Python格式的locustfile.py,然后再传给locust。
至于解析函数parse_locustfile,实现起来也很简单。我们只需要在框架中保存一份locustfile.py的模板文件(ate/locustfile_template),并将testcase_file_path采用占位符代替。然后,在解析函数中,就可以读取整个模板文件,将其中的占位符替换为YAML/JSON用例文件的实际路径,然后再保存为locustfile.py,并返回其路径即可。
具体的代码就不贴了,有兴趣的话可自行查看。
通过这一轮优化,ApiTestEngine就继承了Locust的全部功能,并且可以直接指定YAML/JSON格式的文件启动Locust执行性能测试。
1 | $ locusts -f examples/first-testcase.yml |
优化2:一键启动多个locust实例
经过第一轮优化后,本来应该是告一段落了,因为此时ApiTestEngine已经可以非常便捷地实现接口自动化测试和接口性能测试的切换了。
直到有一天,在TesterHome论坛讨论Locust的一个回复中,@keithmork说了这么一句话。
期待有一天
ApiTestEngine的热度超过Locust本身
看到这句话时我真的不禁泪流满面。虽然我也是一直在用心维护ApiTestEngine,却从未有过这样的奢望。
但反过来细想,为啥不能有这样的想法呢?当前ApiTestEngine已经继承了Locust的所有功能,在不影响Locust已有特性的同时,还可以采用YAML/JSON格式来编写维护测试用例,并实现了一份测试用例可同时用于接口自动化和接口性能测试的目的。
这些特性都是Locust所不曾拥有的,而对于使用者来说的确也都是比较实用的功能。
于是,新的目标在内心深处萌芽了,那就是在ApiTestEngine中通过对Locust更好的封装,让Locust的使用者体验更爽。
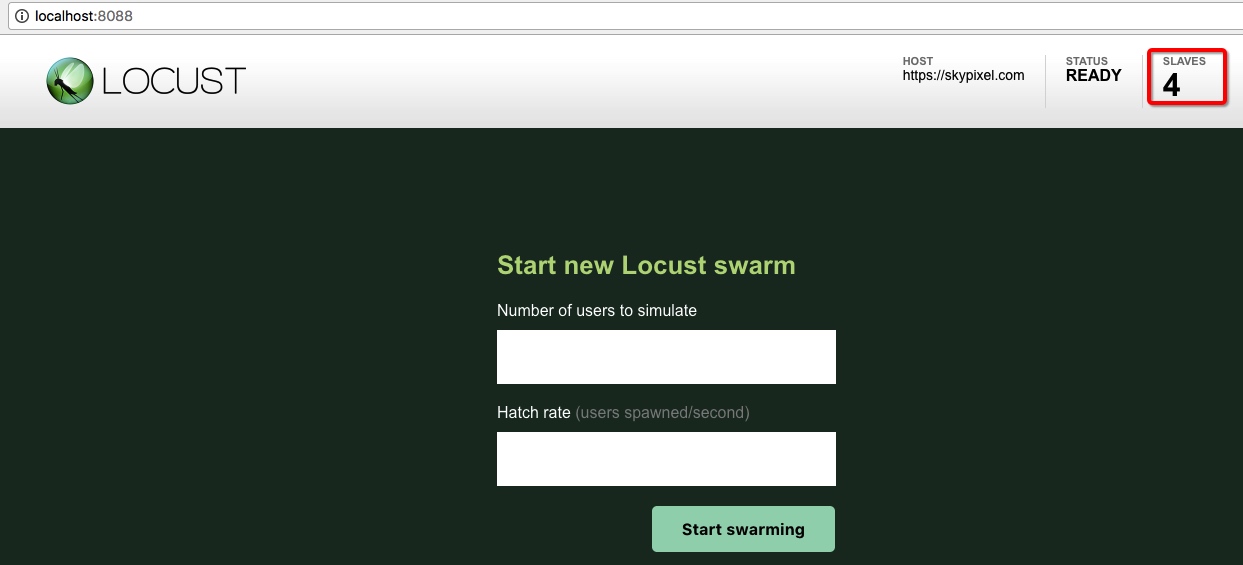
然后,我又想到了自己之前做的一个开源项目,debugtalk/stormer。当时做这个项目的初衷在于,当我们使用Locust进行压测时,要想使用压测机所有CPU的性能,就需要采用master-slave模式。因为Locust默认是单进程运行的,只能运行在压测机的一个CPU核上;而通过采用master-slave模式,启动多个slave,就可以让不同的slave运行在不同的CPU核上,从而充分发挥压测机多核处理器的性能。
而在实际使用Locust的时候,每次只能手动启动master,并依次手动启动多个slave。若遇到测试脚本调整的情况,就需要逐一结束Locust的所有进程,然后再重复之前的启动步骤。如果有使用过Locust的同学,应该对此痛苦的经历都有比较深的体会。当时也是基于这一痛点,我开发了debugtalk/stormer,目的就是可以一次性启动或销毁多个Locust实例。这个脚本做出来后,自己用得甚爽,也得到了Github上一些朋友的青睐。
既然现在要提升ApiTestEngine针对Locust的使用便捷性,那么这个特性毫无疑问也应该加进去。就此,debugtalk/stormer项目便被废弃,正式合并到debugtalk/ApiTestEngine。
想法明确后,实现起来也挺简单的。
原则还是保持不变,那就是不改变Locust本身的特性,只在传参的时候在中间层进行操作。
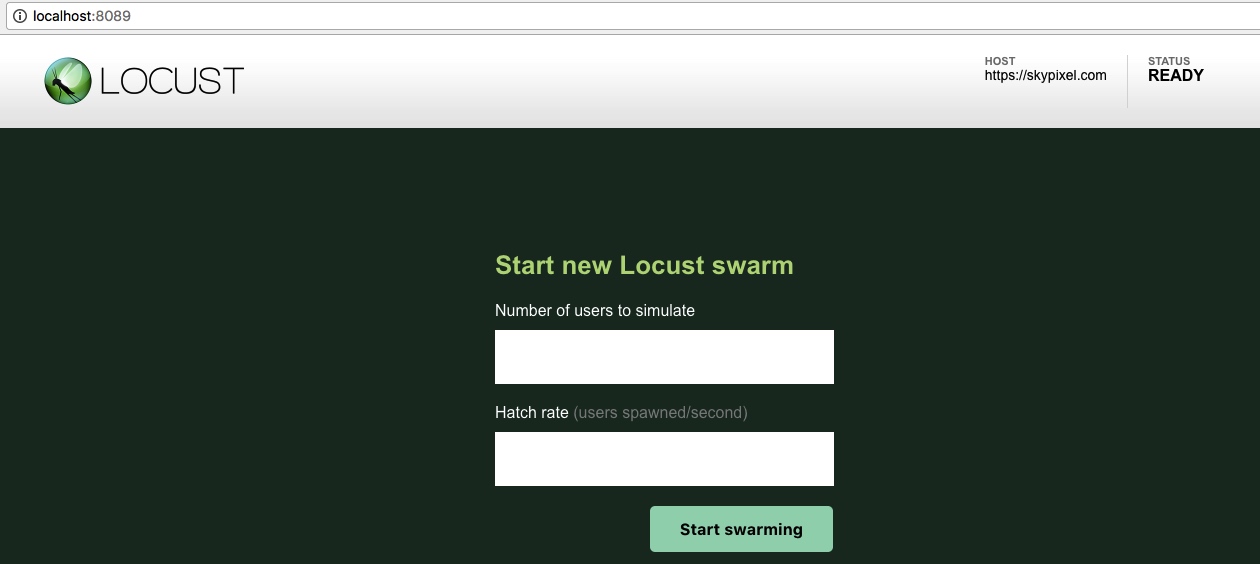
具体地,我们可以新增一个--full-speed参数。当不指定该参数时,使用方式跟之前完全相同;而指定--full-speed参数后,就可以采用多进程的方式启动多个实例(实例个数等于压测机的处理器核数)。
1 | def main_locust(): |
具体实现逻辑在ate/locusts.py中:
1 | import multiprocessing |
由此可见,关键点也就是使用了multiprocessing.Process,在不同的进程中分别调用Locust的main()函数,实现逻辑十分简单。
最终实现效果
经过前面的优化,采用ApiTestEngine执行性能测试时,使用就十分便捷了。
安装ApiTestEngine后,系统中就具有了locusts命令,使用方式跟Locust框架的locust几乎完全相同,我们完全可以使用locusts命令代替原生的locust命令。
例如,下面的命令执行效果与locust完全一致。
1 | $ locusts -V |
差异在于,locusts具有更加丰富的功能。
在ApiTestEngine中编写的YAML/JSON格式的接口测试用例文件,直接运行就可以启动Locust运行性能测试。
1 | $ locusts -f examples/first-testcase.yml |
加上--full-speed参数,就可以同时启动多个Locust实例(实例个数等于处理器核数),充分发挥压测机多核处理器的性能。
1 | $ locusts -f examples/first-testcase.yml --full-speed -P 8088 |
后续,ApiTestEngine将持续进行优化,欢迎大家多多反馈改进建议。
Enjoy!