写在前面
前两天微信突然发来一条系统消息,提示DebugTalk可以开通原创标识了(同时也有了评论功能),虽然一直在期待,但没想到来得这么快,着实是个不小的惊喜。
另外,最近在公众号后台也收到好几个朋友的信息,有的是询问某某部分什么时候能发布,有的是希望能加快更新速度。说实话,收到这样的信息虽然会有压力,但真的挺开心的,因为这说明DebugTalk至少能给一部分人带去价值,这说明这件事本身还是值得坚持去做的。
不过,在更新频率这件事儿上,的确是要跟大家说抱歉了。因为DebugTalk发布的内容全都是原创,主题基本上都是来源于我日常测试工作的经验积累,或者我近期学习一些测试技术的收获总结,这也意味着,我写的东西很多时候并不是自己完全熟悉的(完全掌握的东西也没有足够的动力专门花时间去写)。
就拿最近连载的《从0到1搭建移动App功能自动化测试平台》系列来说,由于我也是边探索边总结,因此中途难免会遇到一些意想不到的坑,造成额外的耗时,而且为了保证文章能尽量通俗易通,我也需要对涉及到的内容充分进行理解,并且经过大量实践进行验证,然后才能站在半个初学者、半个过来人的角度,重新整理思路,最后以尽可能流畅的思路将主题内容讲解清楚。
基于这些原因,DebugTalk要做到每日更新是很难了,但是保证每周发布1~2篇还是可以的,希望大家能理解。
关于UI控件
在上一篇文章中,我们成功地通过Appium Inspector调用模拟器并运行iOS应用,iOS的自动化测试环境也已全部准备就绪了。
那么接下来,我们就可以开始实现自动化测试了么?
貌似还不行。在开始之前,我们先想下什么是APP功能自动化测试。
APP的功能自动化测试,简单地来说,就是让功能测试用例自动地在APP上执行。具体到每一个测试用例,就是能模拟用户行为对UI控件进行操作,自动化地实现一个功能点或者一个流程的操作。再细分到每一步,就是对UI控件进行操作。
因此,在正式开始编写自动化测试用例之前,我们还需要熟悉如何与APP的UI控件进行交互操作。
在iOS系统中,UI控件有多种类型,常见的有按钮(UIAButton)、文本(UIAStaticText)、输入框(UIATextField)等等。但不管是对什么类型的UI控件进行操作,基本都可以分解为三步,首先是获取目标控件的属性信息,然后是对目标控件进行定位,最后是对定位到的控件执行动作。
获取UI控件信息
在Appium中,要获取iOS的UI控件元素信息,可以采用两种方式:一种是在前一篇文章中提到的Appium Inspector,另一种是借助Ruby实现的appium_console,在Terminal中通过命令进行查询。
Appium Inspector
运行Appium Server,并启动【Inspector】后,整体界面如下图所示。
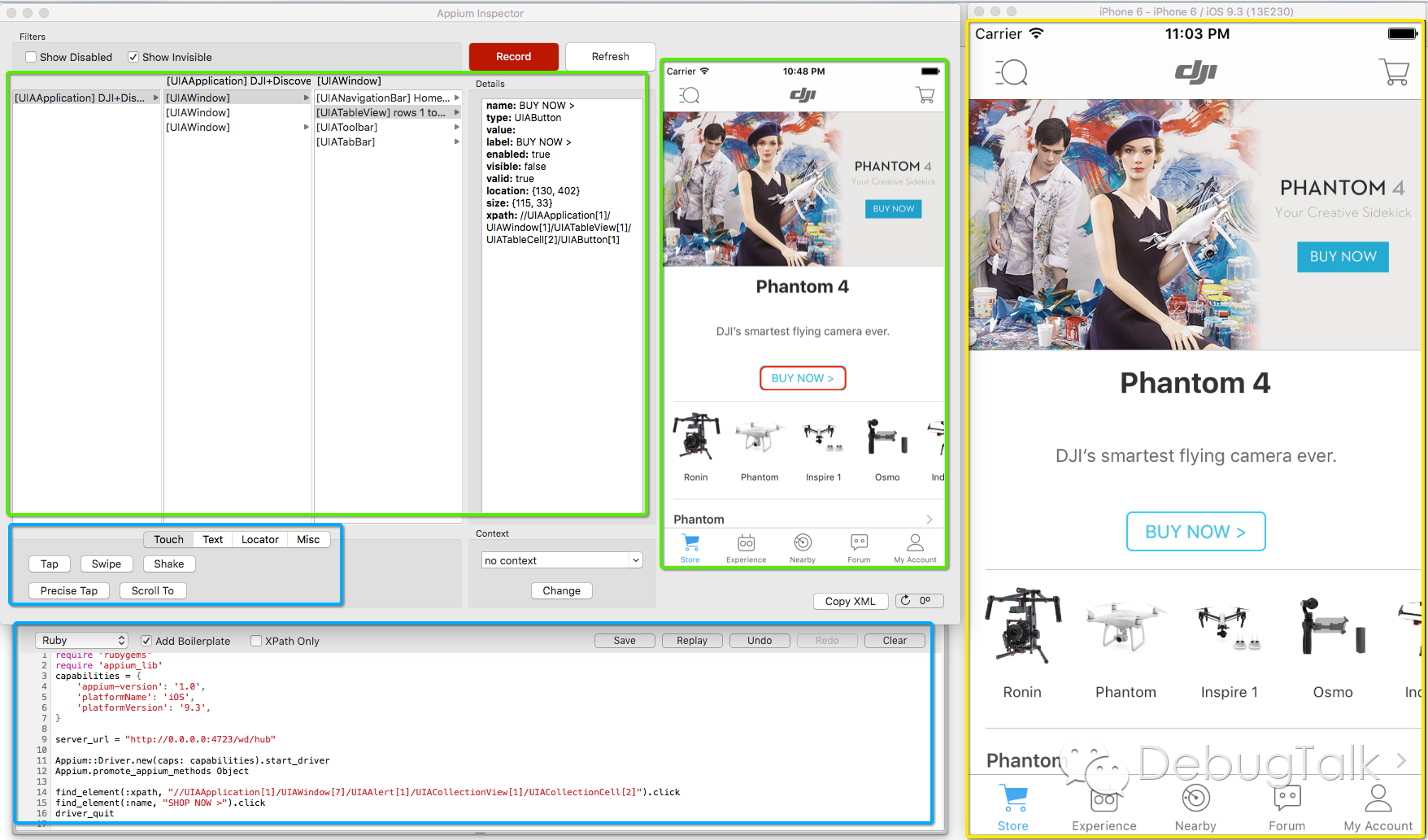
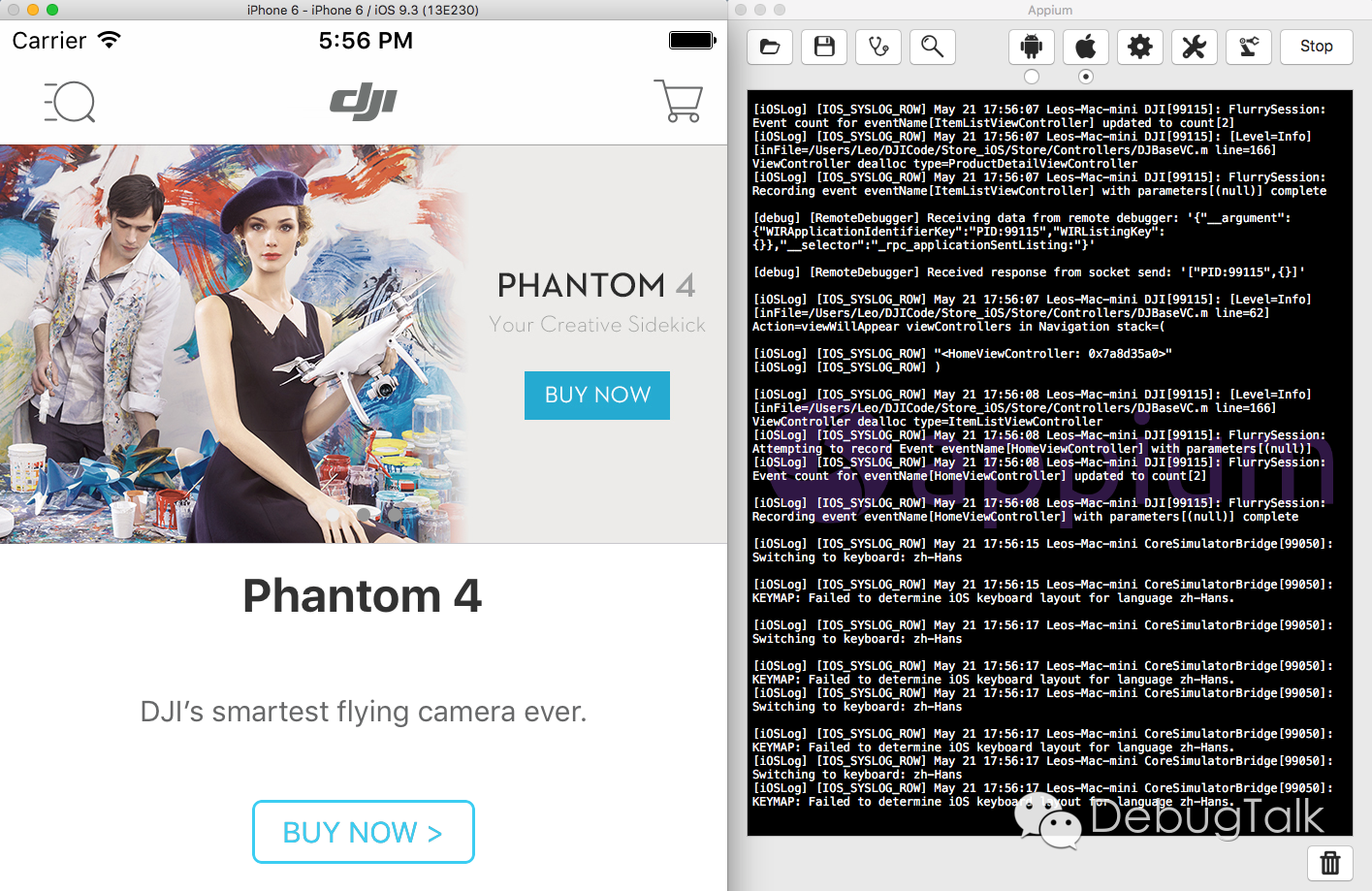
现对照着这张图对Appium Inspector进行介绍。
在右边部分,是启动的模拟器,里面运行着我们的待测APP。我们可以像在真机中一样,在模拟器中执行任意功能的操作,当然,模拟器跟真机毕竟还是有区别的,跟传感器相关的功能,例如摄像头、重力感应等,是没法实现的。
在左边部分,就是Appium Inspector。Inspector主要由如下四个部分组成:
- 预览界面区:显示画面与模拟器界面一致;不过,当我们在模拟器中切换界面后,Inspector的预览区中显示图像并不会自动同步,若要同步,需要点击【Refresh】按钮,然后Inspector会将模拟器当前UI信息dump后显示到预览区;在预览区中,可以点击选择任意UI控件。
- UI信息展示区:展示当前界面预览区中所有UI元素的层级关系和UI元素的详细信息;在预览区中点击选择任意UI控件后,在“Details”信息框中展示选中控件的详细信息,包括name、label、value、xpath等属性值;通过层级关系,我们也能了解选中控件在当前界面树状结构中所处的具体位置。
- 交互操作区:模拟用户在设备上的操作,例如单击(tap)、滑动(swipe)、晃动(shake)、输入(input)等;操作动作是针对预览界面区选中的控件,因此在操作之前,务必需要先在预览区点击选择UI元素。
- 脚本生成区:将用户行为转换为脚本代码;点击【Record】按钮后,会弹出代码区域;在交互操作区进行操作后,就会实时生成对应的脚本代码;代码语言可通过下拉框进行选择,当前支持的语言类型有:C#、Ruby、Objective-C、Java、node.js、Python。
在实践操作中,Inspector最大的用途就是在可以可视化地查看UI元素信息,并且可以将操作转换为脚本代码,这对初学者尤为有用。
例如,在预览区点击选中按钮“BUY NOW”,然后在UI信息展示区的Details窗口就可以看到该按钮的所有属性信息。在交互操作区点击【Tap】按钮后,就会模拟用户点击“BUY NOW”按钮,并且在脚本区域生成当次按钮点击的脚本(选择Ruby语言):
1 | find_element(:name, "BUY NOW >").click |
如上就是使用Appium Inspector的一般性流程。
Appium Ruby Console
有了Appium Inspector,为什么还需要Appium Ruby Console呢?
其实,Appium Ruby Console也并不是必须的。经过与多个熟悉Appium的前辈交流,他们也从未用过Appium Ruby Console,这说明Appium Ruby Console并不是必须的,没有它也不会影响我们对Appium的使用。
但是,这并不意味着Appium Ruby Console是多余的。经过这些天对Appium的摸索,我越发地喜欢上Appium Ruby Console,并且使用的频率越来越高,现在已基本上很少使用Appium Inspector了。这种感觉怎么说呢?Inspector相比于Ruby Conosle,就像是GUI相比于Linux Terminal,大家应该能体会了吧。
Appium Inspector的功能是很齐全,GUI操作也很方便,但是,最大的问题就是使用的时候非常慢,在预览界面区切换一个页面常常需要好几秒,甚至数十秒,这是很难让人接受的。
在上一节中也说到了,Inspector最大的用途就是在可以可视化地查看UI元素信息,并且可以将操作转换为脚本代码。但是当我们对Appium的常用API熟悉以后,我们就不再需要由工具来生成脚本,因为自己直接写会更快,前提是我们能知道目标控件的属性信息(type、name、label、value)。
在这种情况下,如果能有一种方式可以供我们快速查看当前屏幕的控件属性信息,那该有多好。
庆幸的是,在阅读Appium官方文档时,发现Appium的确是支持命令行方式的,这就是Appium Ruby Console。
Appium Ruby Console是采用Ruby语言开发的,在使用方式上面和Ruby的irb很类似。
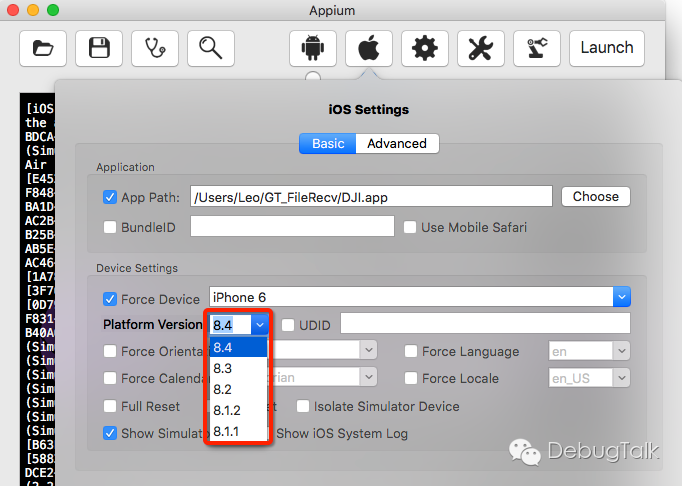
在使用Appium Ruby Console时,虚拟机的配置信息并不会从GUI中读取,而是要通过配置文件进行指定。
配置文件的名称统一要求为appium.txt,内容形式如下所示:
1 | [caps] |
其中,platformName指定虚拟机操作系统类型,“ios”或者”android”;platformVersion指定操作系统的版本,例如iOS的’9.3’,或者Android的’5.1’;app指定被测应用安装包的路径。这三个参数是必须的,与Inspector中的配置也能对应上。
在使用Appium Ruby Console时,首先需要启动Appium Server,通过GUI或者Terminal均可。
然后,在Terminal中,进入到appium.txt文件所在的目录,执行arc命令即可启动Appium Ruby Console。arc,即是appium ruby console首字母的组合。
1 | ➜ ls |
接下来,就可以通过执行命令查询当前设备屏幕中的控件信息。
使用频率最高的一个命令是page,通过这个命令可以查看到当前屏幕中所有控件的基本信息。
例如,当屏幕停留在前面截图中的页面时,执行page命令可以得到如下内容。
1 | [1] pry(main)> page |
通过返回信息,我们就可以看到所有控件的type、name、label、value属性值。如果在某个控件下没有显示label或value,这是因为这个值为空,我们可以不予理会。
由于page返回的信息太多,可能不便于查看,因此在使用page命令时,也可以指定控件的类型,相当于对当前屏幕的控件进行筛选,只返回指定类型的控件信息。
指定控件类型时,可以通过string类型进行指定(如 page “Image”),也可通过symbol类型进行指定(如 page :cell)。指定的类型可只填写部分内容,并且不分区大小写。
1 | [2] pry(main)> page "Image" |
如果需要查看当前屏幕的所有控件类型,可以执行page_class命令进行查看。
1 | [4] pry(main)> page_class |
基本上,page返回的控件信息已经足够满足绝大多数场景需求,但有时候情况比较特殊,需要enabled、xpath、visible、坐标等属性信息,这时就可以通过执行source命令。执行source命令后,就可以返回当前屏幕中所有控件的所有信息,以xml格式进行展现。
定位UI控件
获取到UI控件的属性信息后,就可以对控件进行定位了。
首先介绍下最通用的定位方式,find。通过find命令,可以实现在控件的诸多属性值(name、label、value、hint)中查找目标值。查询时不区分大小写,如果匹配结果有多个,则只返回第一个结果。
1 | [5] pry(main)> find('osmo') |
另一个通用的定位方式是find_element,它也可以实现对所有控件进行查找,但是相对于find,可以对属性类型进行指定。
1 | [7] pry(main)> find_element(:class_name, 'UIATextField') |
不过在实践中发现,采用find、find_element这类通用的定位方式并不好用,因为定位结果经常不是我们期望的。
经过反复摸索,我推荐根据目标控件的类型,选择对应的定位方式。总结起来,主要有以下三种方式。
针对Button类型的控件(UIAButton),采用button_exact进行定位:
1 | [9] pry(main)> button_exact('Login') |
针对Text类型的控件(UIAStaticText),采用text_exact进行定位:
1 | [10] pry(main)> text_exact('Phantom') |
针对控件类型进行定位时,采用tag;如下方式等价于find_element(:class_name, 'UIASecureTextField')。
1 | [11] pry(main)> tag('UIASecureTextField') |
基本上,这三种方式就已经足够应付绝大多数测试场景了。当然,这三种方式只是我个人经过实践后选择的定位方式,除了这三种,Appium还支持很多种其它定位方式,大家可自行查看Appium官方文档进行选择。
另外,除了对控件进行定位,有时候我们还想判断当前屏幕中是否存在某个控件(通常用于结果检测判断),这要怎么做呢?
一种方式是借助于Appium的控件查找机制,即找不到控件时会抛出异常(Selenium::WebDriver::Error::NoSuchElementError);反过来,当查找某个控件抛出异常时,则说明当前屏幕中不存在该控件。
1 | [12] pry(main)> button_exact('Login_invalid') |
该种方式可行,但比较暴力,基本上不会采用这种方式。
另一种更好的方式是,查找当前屏幕中指定控件的个数,若个数不为零,则说明控件存在。具体操作上,将button_exact替换为buttons_exact,将text_exact替换为texts_exact。
1 | [12] pry(main)> buttons_exact('Login').count |
除此之外,基于Ruby实现的appium_lib还支持exists方法,可直接返回Boolean值。
1 | [14] pry(main)> exists { button_exact('Login') } |
对控件执行操作
定位到具体的控件后,操作就比较容易了。
操作类型不多,最常用就是点击(click)和输入(type),这两个操作能覆盖80%以上的场景。
对于点击操作,才定位到的控件后面添加.click方法;对于输入操作,在定位到的输入框控件后面添加.type方法,并传入输入值。
例如,账号登录操作就包含输入和点击两种操作类型。
1 | [16] pry(main)> find_element(:class_name, 'UIATextField').type 'leo.lee@debugtalk.com' |
To be continued …
在本文中,我们学习了对iOS UI控件进行交互操作的一般性方法,为编写自动化测试脚本打好了基础。
在下一篇文章中,我们就要正式开始针对iOS应用编写自动化测试脚本了。