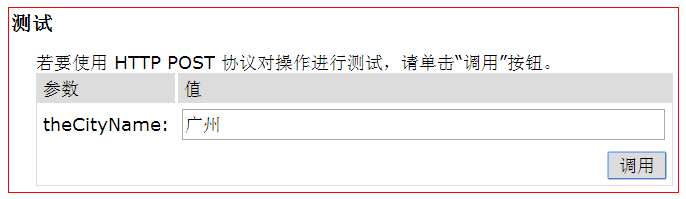
本文通过案例的形式,详细讲解黑盒测试用例设计技术中的等价类划分法。
等价类划分是一种典型的黑盒测试方法,其原理是把程序的输入域划分成若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。
通过等价类划分,可以在尽可能覆盖所有测试路径的前提下,大幅度减少测试用例的数目。
本文的主要内容有:
- 等价类的概念介绍
- 划分等价类的原则
- 根据等价类设计测试用例的方法
- 案例演示
划分等价类
等价类是指某个输入域的子集合。在该子集合中,各个输入数据对于揭露程序中的错误都是等效的。并合理的假设,测试某等价类的代表值就等于对这一类其它值的测试。
等价类划分有两种不同的情况:
- 有效等价类:指对于程序的规格说明来说是合理的、有意义的输入数据构成的集合。
- 无效等价类:指对程序的规格说明是不合理的或无意义的输入数据所构成的集合。对于具体的问题,无效等价类至少应有一个,也可能有多个。
在设计测试用例时,要同时考虑有效等价类和无效等价类,以此验证软件在正常操作和异常操作时是否都能正常运行。
确定等价类的6条原则:
1、在输入条件规定了取值范围或取值的个数的情况下,可以确立一个有效等价类和两个无效等价类。
- 例1:输入值是学生成绩,输入形式为文本框,要求的输入范围是0~100
- 有效等价类:0<=输入成绩<=100;
- 无效等价类1:输入成绩<0;
- 无效等价类2:输入成绩>100
2、在输入条件规定了输入值的集合或者规定了“必须如何”的条件的情况下,可以确立一个有效等价类和一个无效等价类。
- 例2:输入值是人员性别,输入形式为文本框,要求输入的内容必须在集合{男,女}中
- 有效等价类:性别=’男’ 或者 ‘女’
- 无效等价类:性别=’人妖’
3、在输入条件是一个布尔量的情况下,可以确立一个有效等价类和一个无效等价类。
- 例3:输入值是状态标识位“是否完成”,输入形式为单选下拉框,选择范围为{是,否}
- 有效等价类:选项=’是’ 或者 ‘否’
- 无效等价类:未进行选择操作
4、在规定了输入数据的一组值(假设N个),并且程序要对每一个输入值进行处理的情况下,可以确立N个有效等价类和一个无效等价类。
- 例4:输入值是人员性别,输入形式为文本框,要求输入的内容必须在集合{男,女}中;不同的性别选择将跳转至不同的处理页面
- 有效等价类1:性别=’男’
- 有效等价类2:性别=’女’
- 无效等价类:性别=’人妖’
5、在规定了输入数据必须遵守的规则的情况下,可以确立一个有效等价类(符合条件)和若干无效等价类(从各个角度违反规则)。
- 例5:输入值是人员性别,输入形式为单选下拉框,要求输入的内容必须在集合{男,女}中;
- 有效等价类:性别=’男’ 或者 ‘女’
- 无效等价类1:未选择人员性别
- 无效等价类2:在浏览器开发工具中将人员性别的属性值更改为’人妖’
6、在确知已划分的等价类中各元素在程序处理中的方式不同的情况下,则应再将该等价类划分为更小的等价类。
- 例6:在例2(输入值是人员性别,输入形式为文本框,要求输入的内容必须在集合{男,女}中)的基础上,不同的性别选择将跳转至不同的处理页面
- 有效等价类:性别=’男’ 或者 ‘女’
- 有效等价类细分1:性别=’男’
- 有效等价类细分2:性别=’女’
- 无效等价类:性别=’人妖’
- 有效等价类:性别=’男’ 或者 ‘女’
列出等价类表
| 输入条件 | 有效等价类 | 无效等价类 |
|---|---|---|
| … | … | … |
确定测试用例
根据已列出的等价类表,按照如下步骤确定测试用例:
1)为每个等价类规定一个唯一的编号
2)设计一个新的测试用例,使其尽可能多地覆盖尚未覆盖的有效等价类。重复这一步,最后使得所有有效等价类均被测试用例所覆盖。
3)设计一个新的测试用例,使其只覆盖一个无效等价类。重复这一步,使所有无效等价类均被覆盖。
Example1
某程序具有如下功能:输入3个正数a、b、c,分别作为三边的边长构成三角形,输出这3个数所构成的三角形类型。
用等价类划分方法为该程序进行测试用例设计。
划分等价类
分析思路:
步骤一、要求输入3个数,且3个数都为正数;参照规则5,划分为一个有效等价类和三个无效等价类。
- 有效等价类(1):a>0; b>0; c>0;
- 无效等价类(2):a<=0
- 无效等价类(3):b<=0
- 无效等价类(4):c<=0
步骤二、在有效等价类(1)的基础上,参照规则6,对该等价类进行细分;考察3个数能否构成三角形,参照规则5,划分为一个有效等价类和三个无效等价类。
- 有效等价类(5):a>0; b>0; c>0; a+b>c; a+c>b; b+c>a
- 无效等价类(6):a>0; b>0; c>0; a+b<=c
- 无效等价类(7):a>0; b>0; c>0; b+c<=a
- 无效等价类(8):a>0; b>0; c>0; a+c<=b
步骤三、在有效等价类(5)的基础上,参照规则6,对该等价类进行细分;考察3个数能否构成等边三角形,参照规则2,划分为一个有效等价类和一个无效等价类。
- 有效等价类(9):a>0; b>0; c>0; a+b>c; a+c>b; b+c>a; a=b=c
- 无效等价类(10):a>0; b>0; c>0; a+b>c; a+c>b; b+c>a; a!=b 或 b!=c 或 c!=a
步骤四、在无效等价类(10)的基础上,参照规则6,对该等价类进行细分;考察3个数能否构成等腰三角形,参照规则4,划分为三个有效等价类和一个无效等价类。
- 有效等价类(11):a>0; b>0; c>0; a+b>c; a+c>b; b+c>a; a=b!=c
- 有效等价类(12):a>0; b>0; c>0; a+b>c; a+c>b; b+c>a; b=c!=a
- 有效等价类(13):a>0; b>0; c>0; a+b>c; a+c>b; b+c>a; c=a!=b
- 无效等价类(14):a>0; b>0; c>0; a+b>c; a+c>b; b+c>a; a!=b; a!=c; b!=c
设计测试用例
| 序号 | [a,b,c] | 覆盖等价类 | 预期输出结果 |
|---|---|---|---|
| – | – | 覆盖有效等价类 | – |
| 1 | [6,6,6] | (1)(5)(9) | 等边三角形 |
| 2 | [3,3,5] | (1)(5)(10)(11) | 等腰三角形 |
| 3 | [3,4,4] | (1)(5)(10)(12) | 等腰三角形 |
| 4 | [4,5,4] | (1)(5)(10)(13) | 等腰三角形 |
| – | – | 覆盖无效等价类 | – |
| 5 | [3,4,5] | (1)(5)(14) | 一般三角形 |
| 6 | [-1,3,2] | (2) | 不能构成三角形 |
| 7 | [3,-1,2] | (3) | 不能构成三角形 |
| 8 | [3,2,-1] | (4) | 不能构成三角形 |
| 9 | [1,2,3] | (1)(6) | 不能构成三角形 |
| 10 | [3,1,2] | (1)(7) | 不能构成三角形 |
| 11 | [1,3,2] | (1)(8) | 不能构成三角形 |
Example2
某程序具有如下功能:文本框要求输入日期信息,日期限定在1990年1月~2049年12月,并规定日期由6位数字字符组成,前4位表示年,后2位表示月;程序需对输入的日期有效性进行校验。
用等价类划分方法为该程序的“日期检查功能”设计测试用例。
划分等价类
步骤一、要求输入6个数字字符yyyynn;参照规则5,划分为一个有效等价类和三个无效等价类。
- 有效等价类(1):输入6个数字字符
- 无效等价类(2):输入6个字符,存在非数字的情况
- 无效等价类(3):输入少于6个字符
- 无效等价类(4):输入多于6个字符
步骤二、在有效等价类(1)的基础上,参照规则6,对该等价类进行细分;考察6个数是否满足日期格式要求,1990<=yyyy<=2049,01<=nn<=12,参照规则,划分为一个有效等价类和四个无效等价类。
- 有效等价类(5):日期格式满足要求,1990<=yyyy<=2049,01<=nn<=12
- 无效等价类(6):yyyy不满足要求,yyyy<1990
- 无效等价类(7):yyyy不满足要求,yyyy>2049
- 无效等价类(8):nn不满足要求,nn<01
- 无效等价类(9):nn不满足要求,nn>12
设计测试用例
| 序号 | yyyynn | 覆盖等价类 | 预期输出结果 |
|---|---|---|---|
| – | – | 覆盖有效等价类 | – |
| 1 | 199307 | (1)(5) | 日期格式有效 |
| – | – | 覆盖无效等价类 | – |
| 2 | 19June | (2) | 日期格式无效 |
| 3 | 19Jun | (3) | 日期格式无效 |
| 4 | 19June2 | (4) | 日期格式无效 |
| 5 | 198805 | (6) | 日期格式无效 |
| 6 | 205005 | (7) | 日期格式无效 |
| 7 | 198800 | (8) | 日期格式无效 |
| 8 | 199513 | (9) | 日期格式无效 |